robots.txtとは、検索エンジンのクローラーへの指示書となるテキストファイルです。どのページを巡回すべきか、あるいは控えるべきかをクローラーに伝える役割があります。
Webサイトを運営するなかで、「robots.txtとはどのような役割を持ち、どのページを制限すればよいのか」と疑問を抱く方は少なくありません。結論から言うと、検索エンジンに評価される必要のないページへの巡回制限は、サイト全体のSEO評価を効率的に高めるための大切な要素です。
クローラーが巡回してリソースを無駄にしないために、robots.txtで制限すべき項目としては以下があげられます。
この記事では、robots.txtで制限すべき対象や、ステップ、noindexとの明確な違いを解説します。また、よくある質問も紹介していますので、ぜひ参考にしてください。⇒レイアップに相談する(無料)
目次
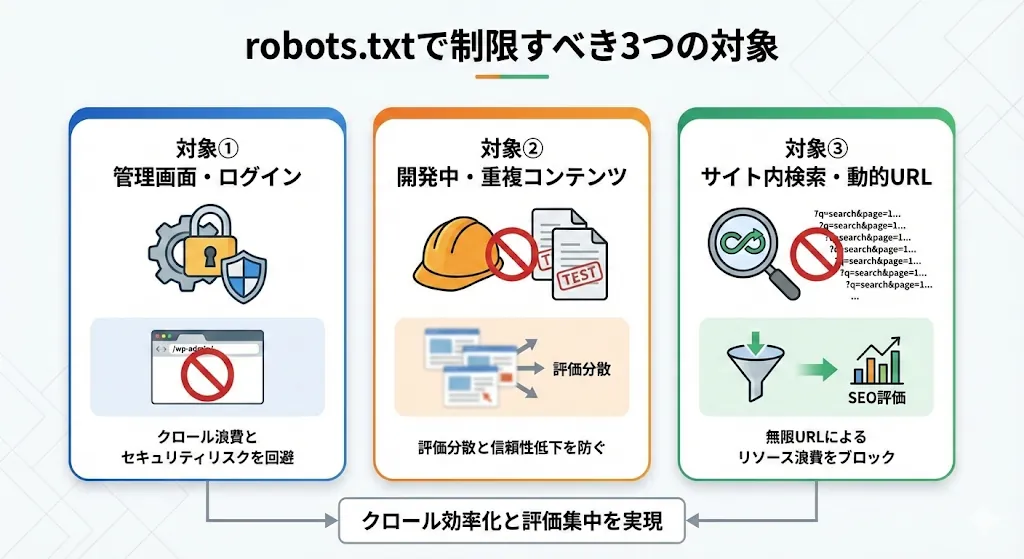
robots.txtで制限すべき3つの対象
サイト内には、クローラーが巡回してリソースを無駄遣いさせてしまうページが存在します。以下の項目を適切にブロックすれば、大切なページにクローラーを集中させられます。
それぞれの詳細について詳しくみていきましょう。
対象①管理画面やログインに関連するページ
管理画面やログインページは、サイト運営者のみが利用する領域であり、一般の検索ユーザーに公開する必要がないページです。WordPressなどのCMSを利用している場合、「/wp-admin/」といったディレクトリには管理用のシステムファイルが多数含まれています。
これらをクローラーが延々と巡回してしまうと、本来評価されるべき新規記事などの巡回頻度が下がる原因になりかねません。また、管理用URLが検索結果に表示されないように制御すれば、不正アクセスのリスクを間接的に下げるセキュリティ上の効果も期待できます。
対象②開発中のテストページや重複コンテンツ
開発中のテストページや内容が酷似した重複コンテンツは、検索エンジンからの評価を著しく分散させる要因となります。テスト環境が誤ってインデックスされると、未完成の情報がユーザーに届いてしまい、サイトの信頼性を損なうリスクがあります。
意図しないページが評価対象に含まれないように、制作段階から特定のディレクトリをブロックする設定を行いましょう。これにより、サイト本来の価値をクローラーに正しく伝え、検索順位を安定させてください。
対象③サイト内検索結果などの動的URL
サイト内検索で生成される動的URLは、条件により無数に増え続けるため、クロールリソースを大幅に浪費します。Googleも、検索結果ページなどの無限に生成されるURLは、クロールをブロックする方法が望ましいと明示しています。
不要なパラメータ付きURLの巡回を制限して、サイトの評価を集中させ、検索エンジンへのインデックスを早めてください。それぞれページの価値を最大限に高め、効率的なサイト運営を実現しましょう。
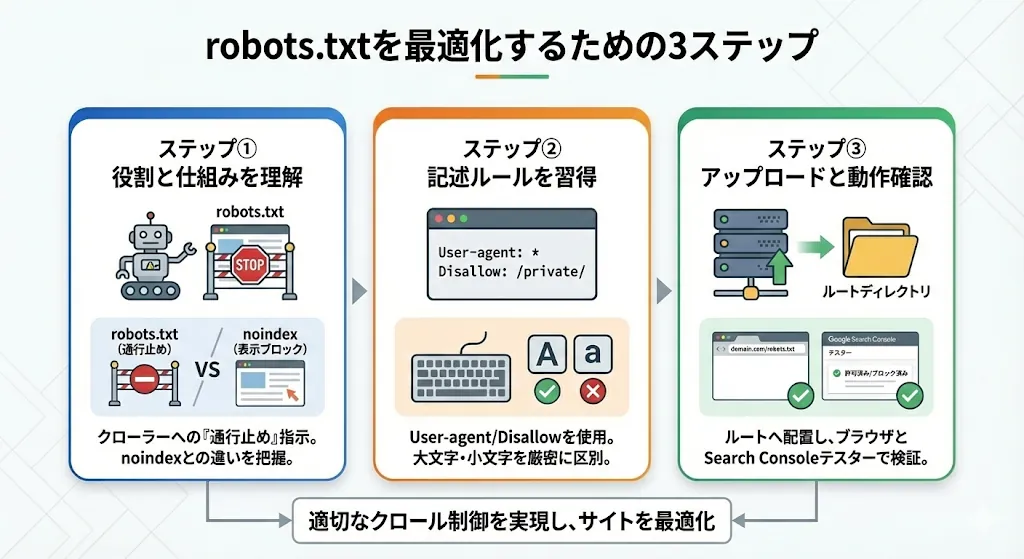
robots.txtを最適化するための3ステップ
robots.txtを正しく運用するステップをご紹介します。
それぞれについて詳しくみていきましょう。
ステップ①役割と仕組みを正しく理解する
robots.txtは、クローラーがサイトを訪れた際、最初に読み取るファイルです。サイト内の「通行止め」を指示する看板のようなもので、「クロールを控えてほしい」というリクエストとして機能します。
また、「検索結果からの除外」を行うnoindexとは役割が異なる点を、まずは明確に把握しましょう。この仕組みを正しく理解しておくことが、適切なクロール制御を行うための強固な土台となります。
なお、SEOの内部施策については、こちらの記事で詳しく解説しています。
関連記事:【初心者向け】SEOの内部対策とは?外部対策との違いや施策内容をわかりやすく解説します!
ステップ②基本的な記述ルールを習得する
robots.txtの記述には、「User-agent」や「Disallow」といった特定の命令語を組み合わせて使用します。対象とするクローラーを指定した後に、拒否したいディレクトリのパスを記述する形式が一般的です。
大文字と小文字が厳密に区別されるため、記述ミスがサイト全体に影響をおよぼす可能性があります。このため、複数の指示がある場合は命令を1行ずつ並べ、視認性の高いファイルを作成しましょう。
参考:robots.txtの書き方|Google検索セントラル
ステップ③サーバーにアップロードして動作確認する
作成したファイルは、必ずサイトのルートディレクトリにアップロードしましょう。ブラウザから「ドメイン名/robots.txt」にアクセスして、内容が正しく表示されるかまず確認します。
また、「Google Search Console」のテスターを利用して、意図した通りに動作しているか検証を行う必要があります。設定にミスがあると、大切なページまでクロールされなくなる恐れがあるため、公開後の動作確認は必ずセットで行ってください。
正しい場所に配置されていないと、クローラーは指示を認識できません。エラーや警告が出ていないかを最終チェックし、サイトの巡回を最適化してください。

robots.txtとnoindexとの明確な3つの違い
robots.txtを正しく扱うためには、目的が似ているnoindexタグとの役割分担を明確に理解しなければなりません。これらを混同して使用すると、検索結果からページが消えない、あるいは意図せず評価を下げるといったトラブルの原因となります。
違い①制御方法
robots.txtは検索エンジンに対して「巡回(クロール)そのもの」を拒否するために使用するファイルです。一方で、noindexタグは「検索結果への登録(インデックス)」を拒否するための指示となります。
Googleは、noindexタグを認識させるためにはまずクローラーがそのページを読み取る必要があると説明しています。ページを検索結果から完全に消したい場合にrobots.txtでブロックしてしまうと、クローラーがnoindexを読み取れず、検索結果に残り続ける点に注意してください。
違い②記述場所
robots.txtは、サイトのルートディレクトリに1つのテキストファイルを設置するだけで、サイト全体を一括で管理可能です。一方で、noindexタグは各ページのHTMLソース内にあるheadセクションに、ページごとに個別に記述しなければなりません。
特定のディレクトリ全体を効率よく制御したい場合は、ファイル1つで完了するrobots.txtの設定が非常に適しています。ページ単位で細かくインデックスの制御を行いたい場合には、noindexの利用がおすすめです。
大規模なサイトを運営する際は、管理の手間を考慮して最適な設置方法を選択してください。一括で制限するか、個別に判断するかによって使い分けることが、サイト運営の効率化に直結します。
違い③SEO効果
robots.txtによる制限は、クローラーが大切なページを優先して巡回できるようにする「クロールバジェット」の最適化に大きく寄与します。noindexは、質の低いページを検索結果から除外すれば、サイト全体のコンテンツ品質を高く保つ効果があります。
サイトの規模が大きいほど、価値の低いページへのクロールを抑える戦略が欠かせません。クロールのリソースを守りつつ、質の高いページだけを検索エンジンに伝えることが、SEOを成功させるための近道となります。
なお、SEOによる効果については、こちらの記事で詳しく解説しています。
関連記事:SEOによる効果とは?効果が出るまでの運用期間や対策、注意点について徹底解説!
robots.txtでよくある3つの質問
robots.txtでよくある質問をご紹介します。それぞれ詳しくみていきましょう。
質問①robots.txtを設置しないとペナルティを受けますか?
robots.txtを設置しないだけで、直接的なペナルティを受けることはありません。Googleはファイルが存在しない場合、サイト上の全ページを巡回してよいと判断するためです。
しかし、不要なページまで巡回されると、重要な記事の評価が遅れる場合があります。リソース消費を抑えサイトの健全性を保つために、サイトマップを記したファイルの設置がおすすめです。
質問②設定が反映されるまでどのくらいの時間がかかりますか?
robots.txtの変更は、クローラーが次にサイトを訪れてファイルを読み込んだタイミングで反映されます。一般的には、数時間から24時間以内に行われる場合が多いですが、サイトのクロール頻度によって前後します。
Googleは、ファイルのキャッシュを最大24時間保持する場合があるため、即座に反映されない場合がある点に注意しなければなりません。早く反映させたい場合は、Google Search Consoleの「robots.txt テスター」から再送信してください。
質問③記述を間違えると、全ページがインデックスから消える場合はありますか?
記述ミスによって、サイト全体が検索結果から消えるリスクはあります。「Disallow: /」という記述を適用してしまうと、ドメイン配下の全ページへの巡回が拒否されてしまいます。
公開前には必ずテスターを利用して、重要なページを誤ってブロックしていないか厳重に確認してください。一度消えた評価を戻すには時間がかかるため、正確な記述を常に心がけましょう。
robots.txtを正しく設定してSEO効果を高めよう!
robots.txtを適切に設定すれば、検索エンジンがサイトを正しく理解して、大切なページを優先的に評価する環境が整います。正しく指示を出せば、サイト全体の評価が向上して、検索順位の安定というポジティブな未来を実現しましょう。以下のステップを順番に実践して、クローラーを最適に誘導してください。
継続的なメンテナンスを心がければ、サイトの成長に合わせて最適なクロール環境を維持し続けられます。Google Search Consoleなどのツールを定期的にチェックして、エラーや意図しないブロックが発生していないか常に確認する習慣を身に付けましょう。